本文共 5829 字,大约阅读时间需要 19 分钟。
本文翻译自 Netflix 工程师合著的 一书。这本书介绍了混沌工程的主要概念,以及如何在组织中实践这些概念和经验。也许我们开发的相关工具只适用于 Netflix 自身的业务和系统环境,但我们相信工具背后的原则可以更广泛地应用于其他领域。
InfoQ 将就这一专题持续出稿,感兴趣的同学可以持续关注。
在和中,我们讨论了混沌工程的初衷和背后的理论。然而将理论付诸实践,是具有挑战性的。任何系统都没有现成的构建、调度,自动化实验的工具,而且即使是最好的混沌工程框架,也需要良好适配才能发挥作用。
混沌工程起源于Netflix,但它的影响力已经从技术领域扩展到了其他行业。在一些会议上,我们经常听到来自金融行业工程师们的一些保留意见。他们不愿实施混沌工程实验的原因是,害怕实验会给客户带来资金或行业合规性的影响。然而我们坚持认为,该发生的故障,不会因为你的意愿而不发生。即使实验暴露风险点的同时会导致一些小的负面影响,提前了解和控制影响范围,也比最终措手不及,应对大规模事故要好得多。现在我们已经看到很多银行和金融公司在实践混沌工程,为那些犹豫不决的企业提供了大量示例参考。
医疗行业的工程师们也表达了类似的疑虑。诚然,娱乐服务的中断只会让人觉得不方便,金融交易的失败令人困惑并且可能导致大量损失,但医疗技术领域的任何失败都可能会危及生命。然而我们还是想指出,激励我们让混沌工程规范化的许多科学原则正是起源于医学。医学研究的最高标准就是临床试验。我们绝不会忽视将混沌工程引入医疗领域的潜在影响,只是想说明,实际生活中已经存在很多具有同样风险的先例,并且已经被广泛接受了。
对混沌工程这样一个新生的学科来说,付诸实践是最有意义和最迫切的。了解关于如何实施、复杂性和实施时需要关注的问题,既可以帮助你找出目前在混沌工程之路上,你所处的位置,也可以指明组织中需要在何处发力来构建成功的混沌工程实践。
8. 设计实验
在讨论完理论原则之后,我们来如何看看设计混沌工程实验的细节。下面是大致的流程:
选定假设;
设定实验的范围;
识别出要监控的指标;
在组织内沟通到位;
执行实验;
分析实验结果;
扩大实验范围;
自动化实验。
8.1 选定假设
你需要做的第一件事就是选定你要验证的假设,我们在中有过讨论。例如,你最近在访问Redis时有超时报错,于是想确保你的系统不会被这类缓存访问超时所影响。再比如,你希望验证主从数据库配置,在主数据库故障时可以无缝切换到从数据库。
不要忘记你的系统中一个重要的组成部分是维护它们的人。人工的行为对于降低事故率至关重要。例如有的公司采用如Slack或HipChat之类的即时通讯工具在故障时的进行沟通,当即时通信工具不可用时,如何处理故障也有一套应急流程。那么如何得知on-call工程师是否掌握了这个应急流程?执行混沌工程实验就是很好的办法。
8.2 设定实验的范围
当选定了要验证的假设,下一步需要做的就是设定好实验的范围。这里有两个原则:“在生产环境运行实验”和“最小化爆炸半径”。实验离生产环境越近,从实验中获得的收益就越大。虽然这么说,但还是要仔细关注可能对系统和用户造成影响的风险。
我们需要尽可能最小化实验对用户造成的影响,应该从一个小范围的测试开始,然后一步步扩大,直到我们认为系统可以应对预期的最大影响。
因此,如中描述过的,我们提倡第一个实验的范围控制得越小越好。而且应该在生产环境中执行实验之前,先在测试环境中试一试。一旦进入生产环境,一定要从最小量的用户流量开始尝试。例如,如果你要验证系统在缓存超时时会怎么做,可以先用一个测试客户端调用生产环境的服务,并且只针对这个客户端引入缓存超时。
8.3 识别出要监控的指标
明确了假设和范围之后,我们需要选定用来评估实验结果的指标,我们在中讨论过。要尽可能基于你的指标来验证假设。例如假设是“主数据库故障时,所有服务都正常”,那么在运行实验之前,你需要清晰定义什么是“正常”。再举个例子,如果你有一个明确的业务指标“每秒订单数”,或者更低级别的指标,像响应时间和响应错误率,在执行实验之前要明确定义清楚这些指标可以容忍的数值范围。
如果实验产生的影响比预期中的大,你就应该准备好立即终止实验。可以预先设定好明确的阈值,例如,失败请求占比不超过5%。这可以帮助你快速决定在实验进行中,要不要按下那个“大红色按钮”。
8.4 在组织内沟通到位
当你第一次在生产环境中执行混沌工程实验时,你需要通知你所在组织中的其他成员,你将要做什么,为什么要做,以及什么时间要做。
第一次执行的时候,你可能需要协调好每个需要参与的,对结果感兴趣的,以及对生产影响有顾虑的团队。随着越来越多次的执行实验,你和你的组织对系统的信心会越来越足,这时就没必要每次都为了实验发送通知了。
关于混乱金刚的通知
我们第一次执行混乱金刚实验,验证AWS区域故障恢复实践时,整个过程中与公司各团队做了大量沟通,目的是让每一个人都清楚我们将在什么时间点让某个区域失效。不可避免地会有很多例如功能发布等的要求,让我们推迟实验。
随着我们一次又一次越来越频繁地进行实验,混乱金刚逐渐被大家接受为一个“常规”事件。结果就是事先沟通越来越少。现在我们每三周执行一次,但已不需要发出通知了。在我们内部有一个可以订阅的日历,标明混乱金刚实验在哪一天执行,但我们不会指明当天具体的执行时间。
8.5 执行实验
截止目前准备工作都已完成,是时候执行实验了!要盯住那些指标,因为你可能随时需要终止实验。随时终止实验的能力异常关键,因为我们是直接在生产环境运行实验,随时都可能对系统造成过度危害,进而影响外部用户。例如一个电商网站,你一定要密切关注用户是否能够正常结算。要确保有足够的报警机制,能实时获知这些关键指标是不是掉到了阈值以下。
8.6 分析实验结果
实验结束后,拿当时的指标数据来验证之前的假设是否成立。系统对于你注入的真实事件是否具备足够的弹性?有没有任何预期之外的事情发生?
多数混沌工程实验暴露出来的问题,都会涉及多服务之间的交互,所以要确保把实验结果反馈给所有相关的团队,一同从整体的角度来消除隐患。
8.7 扩大实验范围
如中描述的,当你从小范围实验中获得了信心之后,就可以逐步扩大实验范围了。扩大实验范围的目的是进一步暴露小范围实验无法发现的一些问题。例如,微服务架构中一些小量的超时或许不会有什么问题,但超过一定比例就可能会导致整体瘫痪。
8.8 自动化实验
如“持续自动化运行实验”一节中描述的,当你有信心手动执行混沌工程实验之后,就可以开始周期性自动化运行实验,持续从中获得更大的价值。
9. 混沌工程成熟度模型
我们标准化混沌工程定义的一个目的是,在执行混沌工程项目时,我们有标准来判断这个项目做得是好是坏,以及如何可以做得更好。混沌工程成熟度模型(CMM)给我们提供了一个评估当前混沌工程项目成熟度状态的工具。把你当前项目的状态放在这个图上,就可以据此设定想要达到的目标,也可以对比其他项目的状态。如果你想要提升这个项目的状态,CMM的坐标轴会给出明确的方向建议,你应该朝哪里努力。
CMM的两个坐标轴分别是“熟练度”和“应用度”。缺乏熟练度时,实验会比较危险、不可靠、且有可能是无效的。缺乏应用度时,所做的实验就不会有什么意义和影响。要在适当的时候变换在两个不同维度的投入,因为在任何一个时期,要发挥混沌工程项目的最大效果需要在这两个维度上保持一定的平衡。
9.1 熟练度
熟练度可以反映出,在你的组织中混沌工程项目的有效性和安全性。项目各自的特性会反映出不同程度的熟练度,有些完全不具备熟练度,而有些可能具备很高的熟练度。熟练度的级别也会因为混沌工程实验的投入程度而有差异。我们对熟练度用入门、简单、高级和熟练四个级别进行描述。
入门
- 未在生产环境中运行实验;
- 全人工流程;
- 实验结果只反映系统指标,而不是业务指标;
- 只对实验对象注入一些简单事件,如“关闭节点”。
简单
- 用复制的生产流量来运行实验;
- 自助式创建实验,自动运行实验,但需要手动监控和停止实验;
- 实验结果反映聚合的业务指标;
- 对实验对象注入较高级的事件,如网络延迟;
- 实验结果是手动整理的;
- 实验是预先定义好的;
- 有工具支持历史实验组和控制组之间的比较。
高级
- 在生产环境中运行实验;
- 自动结果分析,自动终止实验;
- 实验框架和持续发布工具集成;
- 在实验组和控制组之间比较业务指标差异;
- 对实验组引入如服务级别的影响和组合式的故障事件;
- 持续收集实验结果;
- 有工具支持交互式的比对实验组和控制组。
熟练
- 开发流程中的每个环节和任意环境都可以运行实验;
- 全自动的设计、执行和终止实验;
- 实验框架和A/B测试以及其他测试工具集成以最小化影响;
- 可以注入如对系统的不同使用模式、返回结果和状态的更改等类型的事件;
- 实验具有动态可调整的范围以找寻系统拐点;
- 实验结果可以用来预测收入损失;
- 实验结果分析可以用来做容量规划;
- 实验结果可以区分出不同服务实际的关键程度。
9.2 应用度
应用度用来衡量混沌工程实验覆盖的广度和深度。应用度越高,暴露的脆弱点就越多,你对系统的信心也就越足。类似熟练度,我们也对应用度定义了不同级别,分别是“暗中进行”,适当投入度,正式采用和成为文化。
“暗中进行”
- 重要项目不采用;
- 只覆盖了少量系统;
- 组织内部基本没有感知;
- 早期使用者偶尔进行混沌工程实验。
适当投入度
- 实验获得正式批准;
- 工程师兼职进行混沌工程实验;
- 多个团队有兴趣并参与;
- 少数重要服务也会不定期进行混沌工程实验。
正式采用
- 有专门的混沌工程团队;
- 所有故障的复盘都会进入混沌工程框架来创建回归实验;
- 大多数关键服务都会定期进行混沌工程实验;
- 偶尔执行实验性的故障复盘验证,例如“比赛日”的形式。
成为文化
- 所有关键服务都高频率进行混沌实验;
- 多数非关键服务高频率进行混沌实验;
- 混沌工程实验是工程师日常工作的一部分;
- 所有系统组件默认要参与混沌工程实验,不参与需要特殊说明。
9.3 绘制成熟度模型图
绘制成熟度模型图时,以熟练度作为Y轴,应用度作为X轴。会呈现出如下图所示的四个象限。
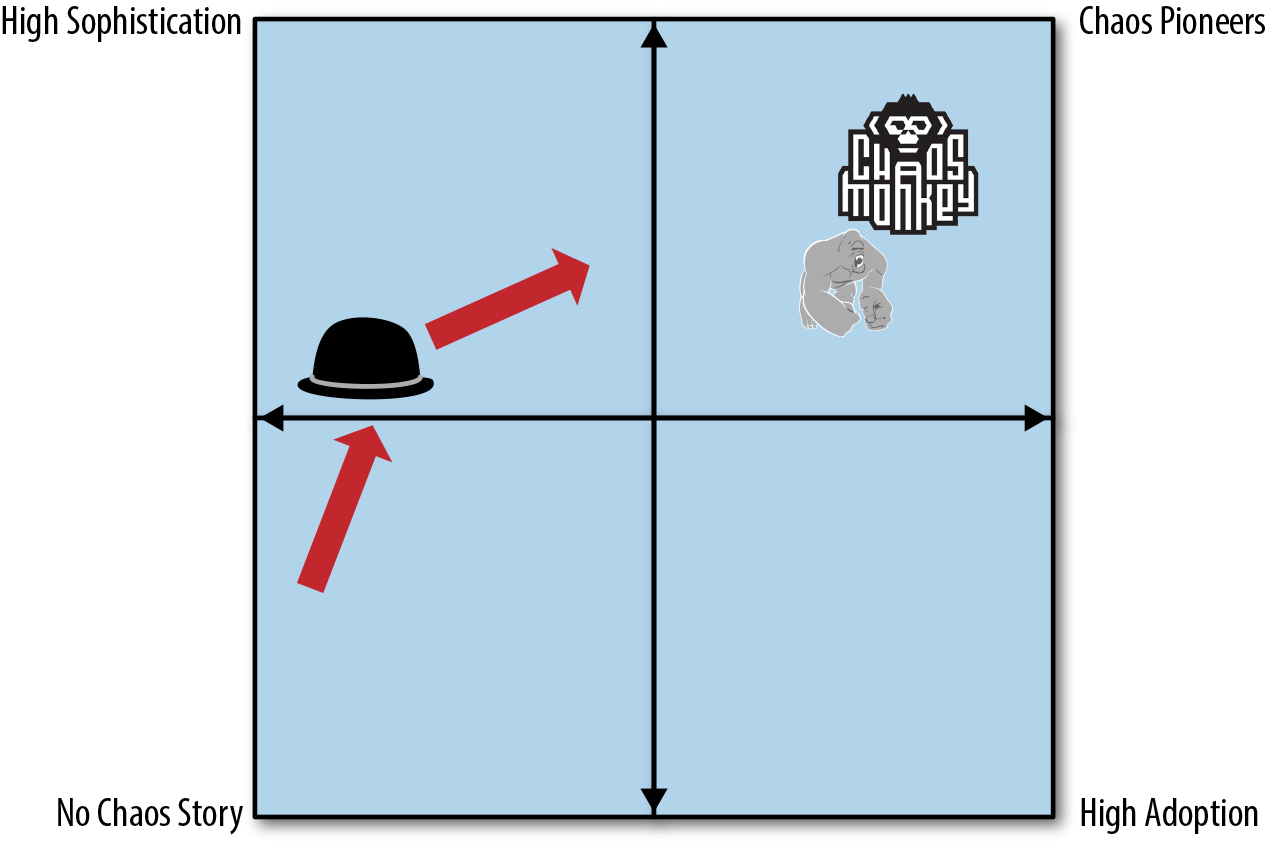
图中我们拿混乱猴子,混乱金刚和混沌工程自动化平台ChAP(帽子)作为示例。写作本文时,我们的ChAP处在熟练度较高的位置,在之前的发展历程中,我们努力的方向如图中箭头所示。现在根据这个图,我们就知道我们需要专注在它的应用度上,以发挥出ChAP的最大潜力。
CMM帮助我们理解混沌工程项目处在什么状态,建议出我们应该聚焦在哪方面来持续提升,同时通过象限图的方式给我们指出改进的方向。
10. 结论
我们相信,在任何开发和运行复杂分布式系统的组织机构里,如果既想拥有高开发效率,又想保障系统具有足够的弹性,那么混沌工程一定是必备的方法。
混沌工程目前还是一个非常年轻的领域,相关的技术和工具也都刚刚开始逐步发展。我们热切的期望各位读者可以加入我们的社区,和我们一起不断实践、拓展混沌工程。
一些资源
我们创建了社区网站 和Google Group 。 期待你加入我们。
你也可以在Netflix的官方博客 找到更多关于混沌工程的信息。当然,还有很多其他的组织在实践混沌工程,例如:
- Fault Injection in Production: Making the Case for Resiliency Testing
- Inside Azure Search: Chaos Engineering
- Organized Chaos With F#
- Chaos Engineering 101
- Meet Kripa Krishnan, Google’s Queen of Chaos
- Facebook Turned Off Entire Data Center to Test Resiliency
- On Designing And Deploying Internet-Scale Services
另外,还有很多为不同场景开发的开源工具:
Simoorg
Linkedin开发的故障注入工具。它非常易于扩展,并且很多关键组件都是可插拔的。
Pumba
基于Docker的混沌工程测试工具以及网络模拟工具。
Chaos Lemur
可以本地部署的随机关闭BOSH虚拟机的工具。
Chaos Lambda
随机关闭AWS ASG节点的工具。
Blockade
基于Docker,可以测试网络故障和网络分区的工具。
Chaos-http-proxy
可以向HTTP请求注入故障的代理服务器。
Monkey-ops
Monkey-Ops用Go实现,可以再OpenShift V3.X上部署并且可以在其中生成混沌实验。Monkey-Ops可以随机停止OpenShift组件,如Pods或者DeploymentConfigs。
Chaos Dingo
Chaos Dingo目前支持在Azure相关服务上进行实验。
Tugbot
Docker生产环境测试工具。
也有一些书籍讲到关于混沌工程的一些主题:
Drift Into Failure by Sidney Dekker (2011)
Dekker的理论讲的是,在一个组织内部,事故的发生都是因为各系统随着时间慢慢滑向一个不安全的状态,而不是某个单点突发的问题造成的。你可以把混沌工程想象成专门用来对抗这种滑动过程的方法。
To Engineer Is Human: The Role of Failure in Successful Design by Henry Petroski (1992)
Petroski描述了他们那里的工程师是如何从过去的失败中汲取教训来进步的,而不是从过去的成功中找经验。混沌工程正是一种既能发现系统中的问题点,又能避免大规模影响的方法论。
Searching for Safety by Aaron Wildavsky (1988)
Wildavksy的主张是,为了提高整体安全性,所有风险必须要被管理好。尤其是采用不断试错的方法,长期来说会比尝试完全避免事故发生,要获得更好的结果。混沌工程也是同样的通过在生产环境进行实验来拥抱风险,以期获得系统更大的弹性的方法。
转载地址:http://trvkx.baihongyu.com/